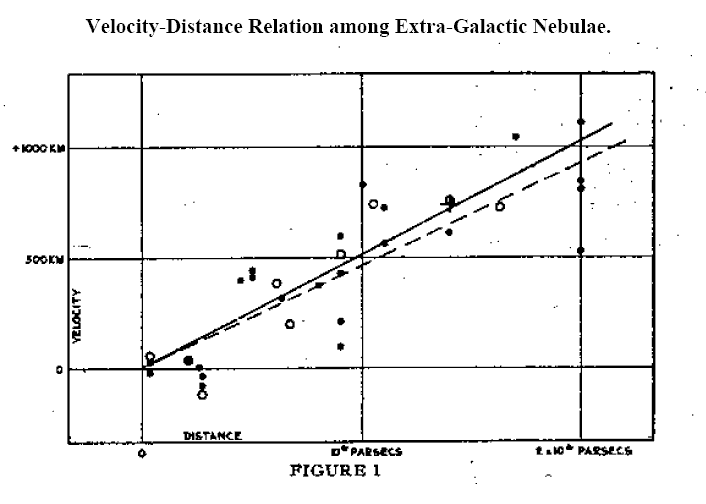
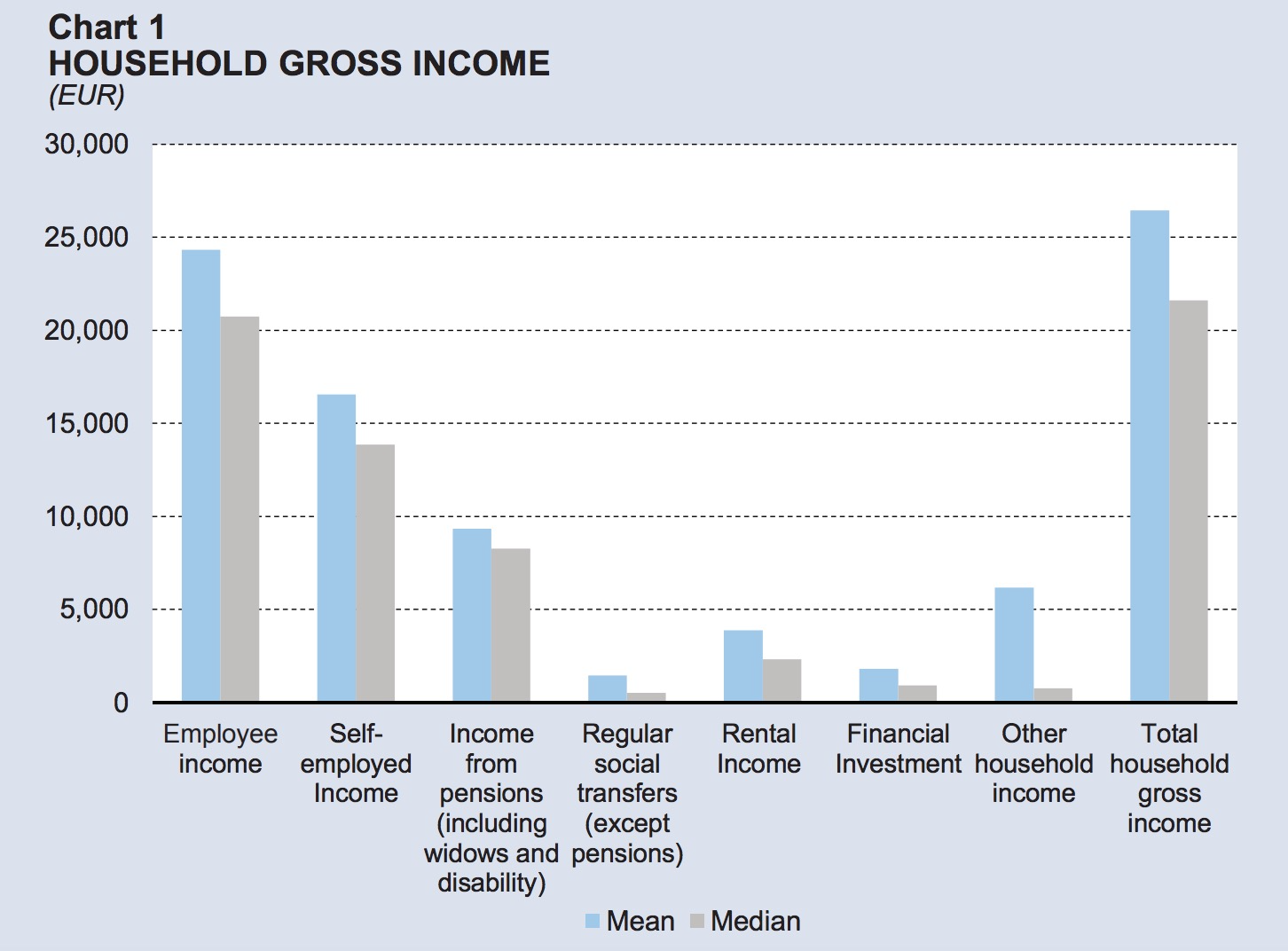
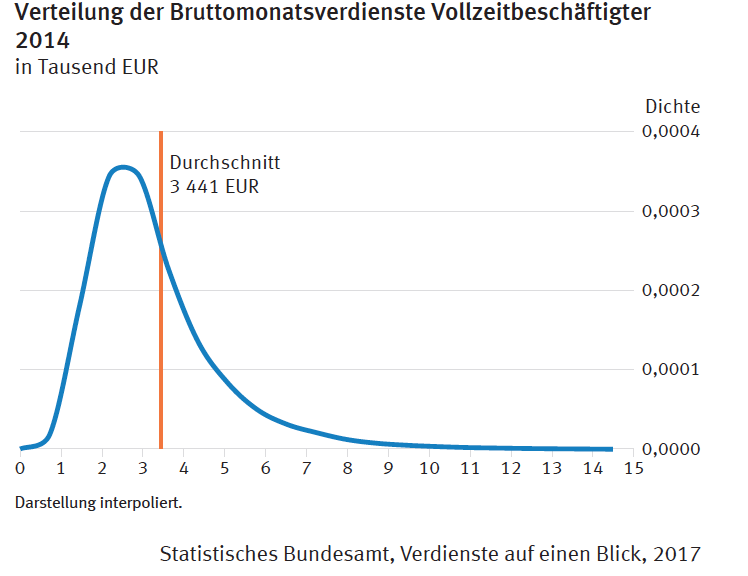
In the spirit of Hitoshi Murayama’s Mac OS X for Physicists, I have compiled a list of Python packages for physicists. This list is not exhaustive – how can it ever be? – but I hope it will serve as a useful compendium for scientists, whether established or aspiring.
General scientific computing
- NumPy — Core array programming for numerical computation.
- SciPy — Scientific algorithms: integration, optimisation, linear algebra, etc.
- SymPy — Symbolic maths in Python (algebra, calculus, tensors).
- matplotlib — Standard Python plotting library.
- Pandas — Data handling and analysis with labelled arrays.
- Jupyter — Interactive coding notebooks for science and documentation.
- Numba — Just-in-time compilation for numerical Python functions.
Cosmology, astrophysics, and astronomy
- Astropy — Core library for astronomy (coordinates, FITS, WCS, units, etc).
- photutils — Source detection and photometry for images.
- astroquery — Query remote databases like SIMBAD, VizieR, NASA, etc.
- APLpy — Astronomical image plotting with celestial coordinates.
- healpy — Healpix-based pixelisation and analysis (e.g. for CMB maps).
- reproject — Reprojection of FITS images between celestial systems.
- sunpy — Solar physics tools for image and data analysis.
- lightkurve — Analyse Kepler and TESS light curves.
- naima — Non-thermal spectral modelling of astrophysical sources.
- Gammapy — High-level gamma-ray data analysis and modelling.
- CosmicPy — Cosmological forecasts and power spectra tools.
- CAMB — CMB anisotropy and matter power spectrum calculations.
- CCL (Core Cosmology Library) — Cosmology functions for structure formation and dark energy.
- LSSTDESC CCL — DESC’s cosmology code for large surveys (LSST, DESI).
- Cobaya — Bayesian inference framework for cosmological model fitting.
- dustmaps — Galactic dust extinction maps and querying tools.
- PyLightcurve — Modelling and fitting exoplanet transit light curves.
- galpy — Galactic dynamics and orbit integration in Milky Way potentials.
- CLASS (classy) — Cosmic Linear Anisotropy Solving System for precision cosmology calculations.
- MontePython — Cosmological MCMC sampler interfaced with CLASS.
General Relativity and gravitational physics
- einsteinpy — General relativity library for black hole physics, geodesics, and spacetime metrics.
- grgrlib — General relativity symbolic tensor computations in Python.
- GenGeo — Geodesic integrator for arbitrary spacetimes.
- SymPy.diffgeom — Differential geometry and tensor calculus in symbolic form.
- Black Hole Perturbation Toolkit — Tools for perturbation theory of black holes (mostly in Mathematica, but conceptually relevant).
Theoretical and particle physics
- mpi4py — MPI bindings for parallel and distributed computing in Python.
- pybinding — Tight-binding simulations in quantum systems and condensed matter physics.
- QuTiP — Simulate quantum systems with decoherence (quantum optics, spin chains, etc).
- Pint — Define, convert, and manipulate physical units and quantities.
- OpenFermion — Fermionic quantum chemistry for quantum computing.
- zfit — Advanced model fitting library used in high-energy physics.
Data analysis, inference, and visualisation
- Seaborn — High-level visualisation built on top of matplotlib.
- Plotly — Interactive, browser-based scientific plots.
- lmfit — Flexible curve fitting with bounds and parameter linking.
- emcee — Affine-invariant MCMC ensemble sampler for Bayesian inference.
- PyMC — Probabilistic programming in Python using HMC and NUTS samplers.
- corner.py — Corner plots for visualising posterior distributions.
- ArviZ — Tools for summarising, visualising, and diagnosing Bayesian inference results.
Experimental physics and instrumentation
- pyserial — Communicate with devices over serial ports.
- PyVISA — Instrument control via GPIB, USB, Ethernet, and serial.
- h5py — Work with HDF5 binary file format for large datasets.
- Bluesky — Experimental control and data collection framework for labs.
Non-Python cosmology packages
Of course I couldn’t leave out the excellent BINGO, developed by my friend and colleague Dhiraj Hazra. As far as I know, it is one of the few codes to compute the primordial power spectrum from the potential itself, and it is certainly the fastest.- BINGO — BI-spectra and Non-Gaussianity Operator: A FORTRAN 90 code that numerically evaluates the scalar bi-spectrum and the non-Gaussianity parameter fNL in single field inflationary models involving the canonical scalar field.